Enterprise AI Infrastruktur: Bewältigen Sie die Herausforderungen von 2026

Infrastruktur-First Enterprise AI: Wie lokale Bereitstellung Kosten senkt und die Umsetzungslücke schließt
Enterprise AI-Akzeptanzraten schnellen in die Höhe, aber die Umsetzung? Genau da scheitert es. Organisationen pumpen Geld in KI-Strategien und Proof-of-Concepts, um dann in dem zu stecken, was ich „Pilot-Fegefeuer“ nenne – unfähig, über Experimente hinaus zu Produktionssystemen zu gelangen, die tatsächlich messbaren Geschäftswert liefern.
Dieser Leitfaden zeigt, wie Infrastruktur-First-Ansätze für die Enterprise AI Infrastruktur Kostenstrukturen transformieren, die Time-to-Value beschleunigen und die Lücke zwischen KI-Ambitionen und operativer Realität durch lokale Bereitstellungsstrategien schließen. Wir werden untersuchen, warum ein Start mit soliden Fundamenten immer besser ist, als glänzenden KI-Funktionen hinterherzujagen.
Definition: Enterprise AI Infrastruktur
Die Enterprise AI Infrastruktur umfasst die integrierte Hardware, Software und den operativen Rahmen, die für die Bereitstellung, Verwaltung und Skalierung von Künstliche Intelligenz-Workloads in Produktionsumgebungen erforderlich sind. Dazu gehören Rechenressourcen mit KI-Beschleunigern, Hochleistungs-Speichersysteme, für ML-Workloads optimierte Netzwerkstrukturen und die Verwaltungsschicht, die diese Komponenten orchestriert. Moderne Enterprise AI Infrastruktur priorisiert Flexibilität zwischen Cloud- und On-Premises-Bereitstellung, während sie Daten-Governance, Sicherheitskontrollen und vorhersehbare Kostenstrukturen aufrechterhält.
Inhaltsverzeichnis
- Die Enterprise AI Umsetzungslücke: Warum die meisten Projekte scheitern
- Infrastruktur-First-Strategie: Von Grund auf bauen
- Cloud-Kostenrealität: Warum Enterprise AI Rechnungen explodieren
- Lokale KI-Bereitstellung: Vorteile bei Kontrolle, Kosten und Compliance
- Dell AI Factory: Moderne On-Premises AI Infrastruktur
- Kostenoptimierungsstrategien für AI Infrastruktur
- Implementierungs-Roadmap: Vom Pilotprojekt zur Produktion
- Agentic AI Systeme und autonome Infrastruktur
- Daten-Governance und Sicherheit bei lokaler KI-Bereitstellung
- ROI-Messrahmen für AI Infrastrukturinvestitionen
- Häufig gestellte Fragen
- Fazit
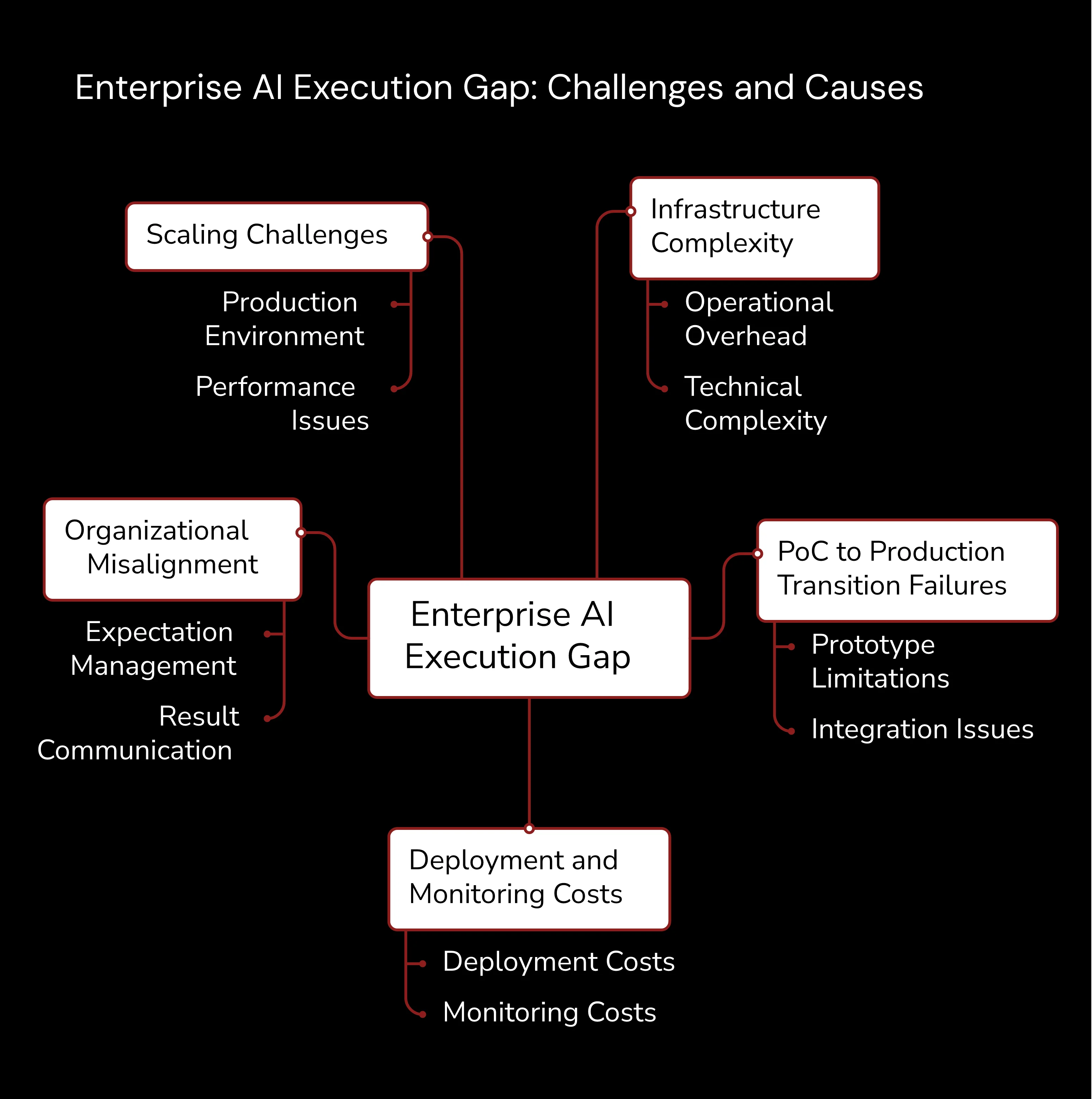
Die Enterprise AI Umsetzungslücke: Warum die meisten Projekte scheitern
Die Enterprise AI Umsetzungslücke stellt den schmerzhaften Abgrund zwischen dem dar, was Unternehmen mit KI erreichen wollen, und dem, was tatsächlich in Produktion geschieht. Mehrere Faktoren tragen zu dieser anhaltenden Herausforderung bei, mit der Technologieführer in allen Branchen konfrontiert sind. Das Muster wiederholt sich überall: große Versprechungen, noch größere Budgets und enttäuschende Ergebnisse.
Die Komplexität der Infrastruktur ist der Hauptgrund für den Misserfolg bei der KI-Umsetzung. Organisationen unterschätzen die betrieblichen Gemeinkosten, die für die Bereitstellung, Überwachung und Wartung von KI-Systemen in großem Maßstab erforderlich sind, durchweg. Entwicklungsteams erstellen Proof-of-Concepts auf Laptops oder begrenzten Cloud-Instanzen und werden dann mit der Realität konfrontiert, wenn Produktionsanforderungen Enterprise-grade Infrastruktur mit hoher Verfügbarkeit, Sicherheitskontrollen und Leistungsgarantien erfordern. Die Kluft zwischen experimentellen Umgebungen und Produktionsanforderungen erweist sich oft als unüberwindbar ohne erhebliche zusätzliche Investitionen. Dort sterben die meisten Projekte.
58 % der Unternehmen
überschritten ihre Schätzungen für die AI Infrastruktur um mehr als 40 %, was zu Budgetüberschreitungen führte, die Projektverzögerungen oder -stornierungen erzwangen (Medha Cloud, 2026).
Qualifikations- und Ressourcenengpässe verstärken die Herausforderungen bei der Ausführung auf eine Weise, die Führungskräfte kalt erwischt. KI-Projekte erfordern gleichzeitig spezialisiertes Fachwissen in den Bereichen Machine Learning Operations, Infrastrukturmanagement und Data Engineering. Die meisten Unternehmen verfügen nicht über die funktionsübergreifenden Teams, die erforderlich sind, um Data-Science-Fähigkeiten mit den Anforderungen des Produktionstechnik zu verbinden. Diese Lücke schafft Engpässe, die Projektlaufzeiten verlängern und die Wahrscheinlichkeit der Akkumulation technischer Schulden in KI-Systemen erhöhen. Man kann dieses Problem nicht einfach über Nacht durch Einstellung lösen.
Governance- und Compliance-Anforderungen fügen der Enterprise AI Ausführung eine weitere Komplexitätsebene hinzu, die im schlimmstmöglichen Moment auftaucht. Organisationen müssen Daten lineage Tracking, Modellversionierung, Audit-Trails und Regulatorische Compliance-Frameworks implementieren, bevor KI-Systeme sensible Geschäftsdaten verarbeiten können. Diese Anforderungen treten oft spät in Projektlebenszyklen auf und zwingen Teams, Governance-Funktionen in Systeme nachzurüsten, die ohne diese Einschränkungen konzipiert wurden. Die daraus resultierenden technischen Schulden und architektonischen Kompromisse verurteilen Projekte häufig zu einem dauerhaften Pilotstatus.
Infrastruktur-First-Strategie: Von Grund auf bauen
Infrastruktur-First-Ansätze für die Enterprise AI drehen traditionelle Implementierungsstrategien um, indem sie produktionsreife Grundlagen schaffen, bevor spezifische KI-Anwendungen entwickelt werden. Diese Methodik behebt die Grundursachen von KI-Ausführungsproblemen durch systematischen Kapazitätsaufbau. Stellen Sie es sich so vor, als würde man das Autobahnsystem bauen, bevor man die Verkehrsrouten plant.
Das Infrastruktur-First-Modell beginnt mit einer umfassenden Planung der Rechenressourcen, die tatsächlich reale Workloads berücksichtigt. Organisationen bewerten ihre KI-Anforderungen über Trainings-, Inferenz- und Datenverarbeitungsaufgaben hinweg, um optimale Hardwarekonfigurationen zu bestimmen. Dies umfasst die Auswahl geeigneter GPU-Beschleuniger, die Planung von Speicher- und Speicherkapazität sowie das Design von Netzwerkarchitekturen, die leistungsstarke KI-Operationen unterstützen. Durch die Schaffung robuster Rechengrundlagen von Anfang an vermeiden Teams Leistungsengpässe, die reaktive Infrastrukturansätze plagen.
Speicher- und Datenplattformdesign erhalten in Infrastruktur-First-Strategien die gleiche Priorität, da Datenzugriffsmuster die KI-Leistung maßgeblich beeinflussen. KI-Anwendungen erfordern einen Hochleistungszugriff auf große Datensätze, was Speichersysteme erfordert, die sowohl auf Durchsatz als auch auf IOPS optimiert sind. Moderne Enterprise AI Infrastruktur umfasst NVMe-Speicherebenen, verteilte Dateisysteme und Data-Lake-Architekturen, die sowohl strukturierte als auch unstrukturierte Datenzugriffsmuster unterstützen. Diese Grundlage ermöglicht es Datenwissenschaftlern, sich auf die Modellentwicklung zu konzentrieren, anstatt mit Produktivität störenden Datenzugriffsbeschränkungen zu kämpfen.
Vorteile der Plattformstandardisierung
Standardisierte KI-Plattformen reduzieren die betriebliche Komplexität und verbessern gleichzeitig die Effizienz der Ressourcennutzung auf breiter Front. Unternehmen setzen konsistente Toolchains, Laufzeitumgebungen und Verwaltungsschnittstellen für alle KI-Projekte ein. Diese Standardisierung beschleunigt das Onboarding von Entwicklern, vereinfacht die Fehlerbehebung und ermöglicht die gemeinsame Nutzung von Ressourcen zwischen Projekten. Teams verbringen weniger Zeit mit der Infrastrukturkonfiguration und mehr Zeit mit wertschöpfenden KI-Entwicklungsaktivitäten. Dort geschieht die eigentliche Magie.
Container-Orchestrierung und MLOps-Pipelines bilden Kernkomponenten standardisierter KI-Plattformen, die tatsächlich in der Produktion funktionieren. Kubernetes bietet Workload-Scheduling und Ressourcenmanagement-Funktionen, die für Multi-Tenant-KI-Umgebungen unerlässlich sind. MLOps-Pipelines automatisieren die Workflows für Modelltraining, -validierung, -bereitstellung und -überwachung, reduzieren manuelle Eingriffe und verbessern die Systemzuverlässigkeit. Diese Plattformfunktionen verwandeln die KI-Entwicklung von einem handwerklichen Prozess in eine Ingenieurdisziplin mit wiederholbaren Prozessen und vorhersehbaren Ergebnissen.
Cloud-Kostenrealität: Warum Enterprise AI Rechnungen explodieren
Die Cloud-Kostenoptimierung wird entscheidend, da KI-Workloads über experimentelle Phasen hinaus in echte Geschäftsanwendungen skaliert werden. Das Verständnis von Cloud-Preismodellen und Kostentreibern ermöglicht es Organisationen, informierte Entscheidungen ↗ über die Infrastruktur zu treffen. Der Preisschock kommt oft zu spät, um den Kurs zu ändern.
GPU-Rechenkosten sind der größte Bestandteil der Cloud-KI-Ausgaben und steigen schneller, als die meisten Finanzteams erwarten. Große Cloud-Anbieter verlangen Premium-Tarife für KI-optimierte Instanzen, wobei die Kosten schnell steigen, wenn Workloads leistungsstärkere Beschleuniger erfordern. Das Training großer Sprachmodelle oder Computer-Vision-Systeme kann Tausende von Dollar an Rechenguthaben innerhalb von Stunden verbrauchen. Organisationen unterschätzen diese Kosten in Pilotphasen häufig, was zu Budgetschocks führt, wenn auf Produktions-Workloads skaliert wird.
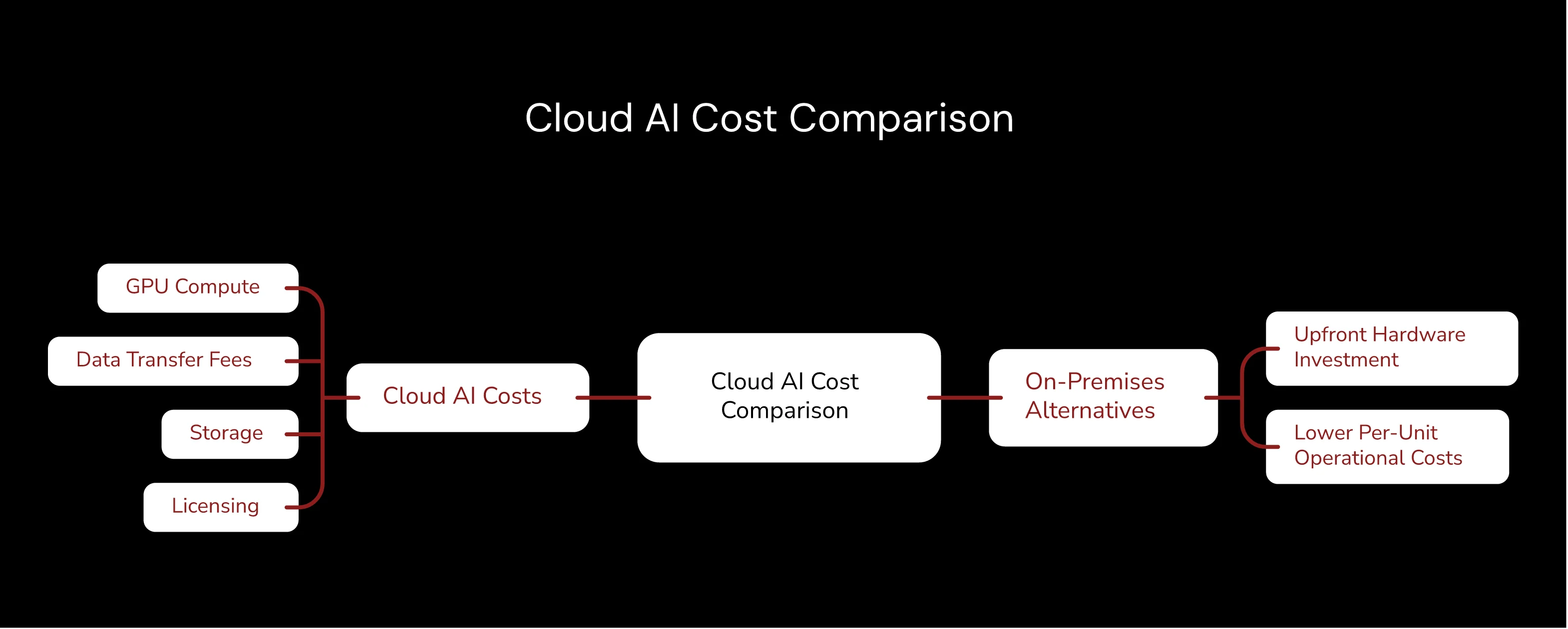
Kostenkategorie | Typischer Cloud-Impact | On-Premises-Alternative |
|---|---|---|
GPU-Berechnung | Variable Stundensätze | Feste amortisierte Kosten |
Datenübertragung | Egress-Gebühren sammeln sich an | Lokales Netzwerk inklusive |
Speicherung | Monatliche Gebühren pro GB | Großinvestition in Kapazität |
API-Aufrufe | Abrechnung pro Anfrage | Unbegrenzte lokale Inferenz |
Datenübertragungskosten erzeugen zusätzlichen finanziellen Druck in Cloud-Umgebungen, der Teams überrascht. KI-Anwendungen erfordern oft häufige Datenübertragungen zwischen Speichersystemen, Rechenressourcen und externen Diensten. Cloud-Anbieter berechnen erhebliche Egress-Gebühren für die Datenübertragung, insbesondere beim Übertragen großer Datensätze oder Modellartefakte. Diese Kosten summieren sich, wenn KI-Systeme skalieren und mehr Datenprodukte generieren. Was als Kleingeld beginnt, wird schnell zu echtem Geld.
Die Unvorhersehbarkeit der Cloud-KI-Kosten stellt Finanzplanung und Budgetkontrolle auf eine Weise in Frage, die Finanzvorstände nachts wach hält. Nutzungsbasierte Preismodelle erschweren die Prognose monatlicher Ausgaben, insbesondere für experimentelle oder saisonale KI-Workloads. Organisationen erleben häufig Kostenspitzen während der Modelltrainingsphasen oder Datenverarbeitungszyklen, was zu Budgetüberschreitungen und einer kritischen Prüfung der KI-Investitionen durch die Führungsebene führt. Finanzteams hassen Überraschungen, und Cloud-KI-Kosten liefern reichlich davon.
Lokale KI-Bereitstellung: Vorteile bei Kontrolle, Kosten und Compliance
Die lokale KI-Bereitstellung bietet Unternehmen überzeugende Vorteile, die vorhersagbare Kosten und eine verbesserte Kontrolle über ihre KI-Infrastruktur suchen. On-Premises-Lösungen beheben viele Einschränkungen, die Cloud-basierte KI-Plattformen mit sich bringen. Die Vorteile werden offensichtlich, sobald man die langfristigen Betriebskosten und Sicherheitsanforderungen berücksichtigt.
Kostenprognostizierbarkeit stellt den unmittelbarsten Vorteil der lokalen KI-Bereitstellung dar, den Finanzteams tatsächlich schätzen. Organisationen investieren in Hardware-Assets mit bekannten Abschreibungsplänen, anstatt in variable Betriebskosten, die wild schwanken. Dieses Investitionsmodell ermöglicht eine genaue langfristige Kostenprognose und eliminiert unerwartete Nutzungsspitzen, die Cloud-Deployments plagen. Finanzteams schätzen die Budgetsicherheit, die die lokale Infrastruktur bietet, insbesondere bei der Planung mehrjähriger KI-Initiativen.
„Der wahre Wert von On-Premises-KI liegt nicht nur in der Kostenkontrolle – er ist die architektonische Freiheit, genau das zu bauen, was Ihr Unternehmen benötigt.“
Datenhoheit und regulatorische Compliance sprechen für lokale Bereitstellungsstrategien auf eine Weise, die Cloud-Anbieter einfach nicht erreichen können. Organisationen behalten die vollständige Kontrolle über den Datenstandort, die Zugriffsmuster und die Aufbewahrungsrichtlinien, ohne auf Compliance-Zertifizierungen Dritter angewiesen zu sein. Diese Kontrolle erweist sich als unerlässlich für Branchen, die strengen regulatorischen Anforderungen unterliegen, wie das Gesundheitswesen, Finanzdienstleistungen und der öffentliche Sektor. Die lokale Bereitstellung eliminiert Bedenken hinsichtlich Verletzungen der Datenresidenz und Risiken des Zugriffs Dritter, die mit Cloud-Diensten verbunden sind.
Die Leistungsoptimierung erreicht in lokalen Bereitstellungen höhere Niveaus, bei denen Organisationen den gesamten Infrastruktur-Stack vom Silizium bis zur Software kontrollieren. Kundenspezifische Netzwerkkonfigurationen, spezialisierte Speichersysteme und optimierte Compute-Cluster können spezifisch für die Anforderungen von KI-Workloads abgestimmt werden. Dieses Optimierungsniveau erweist sich oft als unmöglich in Multi-Tenant-Cloud-Umgebungen, wo Infrastrukturressourcen mehreren Kunden mit konkurrierenden Anforderungen gemeinsam genutzt werden.
Vorteile für Datenschutz und Sicherheit
Die lokale KI-Bereitstellung stärkt die Sicherheitslage, indem externe Netzwerkabhängigkeiten und Risiken des Zugriffs durch Dritte, die Cloud-Umgebungen plagen, eliminiert werden. Sensible Geschäftsdaten bleiben innerhalb der Organisationsgrenzen während des gesamten KI-Pipelines, von der Rohdatenerfassung über das Modelltraining bis zur Inferenzbereitstellung. Dieser Ansatz erfüllt strenge Sicherheitsanforderungen, ohne die KI-Fähigkeit oder Leistung zu beeinträchtigen. Sicherheitsteams schlafen besser, wenn sie genau wissen, wo ihre Daten leben.
Netzwerkisolierungsfunktionen in lokalen Bereitstellungen übertreffen Cloud-Alternativen um Größenordnungen. Organisationen können air-gapped KI-Umgebungen für hochsensible Anwendungen implementieren oder Netzwerksegmentierungsstrategien einsetzen, die KI-Workloads von allgemeinen Geschäftsnetzwerken isolieren. Diese Sicherheitsarchitekturen bieten mehrfach gestaffelten Schutz und behalten gleichzeitig die operative Flexibilität bei, die Cloud-Shared-Responsibility-Modelle nicht bieten können.
Dell AI Factory: Moderne On-Premises AI Infrastruktur
Die Dell AI Factory stellt einen umfassenden Ansatz für die Enterprise AI Infrastruktur dar, der Hardware, Software und Dienstleistungen zu integrierten Lösungen kombiniert, die tatsächlich zusammenarbeiten. Diese Plattform begegnet den gängigen Herausforderungen bei der KI-Bereitstellung durch validierte Referenzarchitekturen und professionellen Service-Support. Der integrierte Ansatz eliminiert die Integrationsschwierigkeiten, die so viele KI-Projekte scheitern lassen.
Die Architektur der Dell AI Factory umfasst für KI-Workloads optimierte PowerEdge-Server mit NVIDIA-, Intel- und AMD-Beschleunigern, die für maximale Leistung ab Werk konfiguriert sind. Diese Systeme umfassen Hochbandbreiten-Speicher, NVMe-Speicherarrays und spezialisierte Netzwerkstrukturen, die für anspruchsvolle KI-Anwendungen entwickelt wurden. Der integrierte Ansatz eliminiert Kompatibilitätsprobleme und reduziert die Bereitstellungskomplexität im Vergleich zu einer komponentenweisen Infrastrukturkonstruktion, die oft zu Schuldzuweisungen zwischen Anbietern führt.
Aktuelle Ankündigungen auf der Dell Technologies World 2026 führten Dell Deskside Agentic AI ein, das es Unternehmen ermöglicht, autonome KI-Agenten lokal ohne Cloud-Abhängigkeiten oder laufende Abonnementgebühren zu betreiben. Diese Funktion ermöglicht den Einsatz von agentischen KI-Systemen in Unternehmensumgebungen unter Beibehaltung der Datenschutz- und Sicherheitskontrollen, die Compliance-Teams fordern. Die Lösung zeigt, wie On-Premises AI Infrastruktur fortschrittliche KI-Fähigkeiten unterstützen kann, die traditionell mit Cloud-Plattformen verbunden sind.
Ökosystem-Partnerschaften und Integration
Das Dell AI Ecosystem Program validiert Software und KI-Modelle von Drittanbietern auf Kompatibilität mit der Dell AI Factory Infrastruktur und eliminiert so die Integrationsrisiken, die kundenspezifische Bereitstellungen plagen. Dieser Validierungsprozess reduziert Integrationsrisiken und beschleunigt die Bereitstellungszeiten, indem er vorab getestete Kombinationen von Hardware- und Softwarekomponenten liefert. Zu den Partnern gehören große KI-Plattform-Anbieter, Modell-Anbieter und spezialisierte KI-Anwendungsentwickler, die die harte Arbeit der Testkombinationen bereits erledigt haben.
Strategische Partnerschaften mit OpenAI ↗, NVIDIA und anderen KI-Leadern ermöglichen die lokale Bereitstellung von hochmodernen KI-Modellen über Dell-Infrastruktur, ohne auf modernste Funktionen verzichten zu müssen. Diese Partnerschaften bringen Cloud-native KI-Fähigkeiten in Unternehmensrechenzentren, während die lokale Kontrolle über Daten und Operationen erhalten bleibt. Der Ansatz zeigt, wie On-Premises-Infrastruktur auf fortschrittliche KI-Technologien zugreifen kann, ohne die Sicherheits- oder Governance-Anforderungen zu opfern, die für Unternehmenskäufer wichtig sind.
Kostenoptimierungsstrategien für AI Infrastruktur
Eine effektive Kostenoptimierung erfordert systematische Ansätze zur Planung der KI-Infrastruktur und zum Ressourcenmanagement, die über einfache Budgetkürzungen hinausgehen. Unternehmen müssen Leistungsanforderungen mit Budgetbeschränkungen in Einklang bringen, während sie für zukünftiges Wachstum planen, das die Bank nicht sprengt. Eine intelligente Optimierung verbessert tatsächlich die Leistung und senkt gleichzeitig die Kosten.
- Workload-Analyse – KI-Anwendungen profilieren, um Compute-, Speicher- und Storage-Anforderungen in verschiedenen Betriebsphasen zu verstehen
- Ressourcen-Pooling – Infrastrukturressourcen projektreitig teilen, um die Auslastungsraten zu verbessern und die Kosten pro Projekt zu reduzieren
- Lebenszyklusmanagement – Hardware-Erneuerungszyklen an Technologie-Fortschrittskurven und Abschreibungspläne anpassen
- Energieeffizienz – Stromsparende Komponenten auswählen und Kühlstrategien implementieren, um Betriebskosten zu minimieren
- Investition in Automatisierung – Infrastruktur-Automatisierungstools einsetzen, um den manuellen Betriebsaufwand zu reduzieren und die Systemzuverlässigkeit zu verbessern
Die Ressourcendimensionierung verhindert eine Überprovisionierung und gewährleistet gleichzeitig eine angemessene Leistung für KI-Workloads, die für das Unternehmen tatsächlich wichtig sind. Unternehmen sollten die tatsächlichen Ressourcennutzungsmuster überwachen, anstatt sich auf theoretische Maximalanforderungen zu verlassen, die in der Praxis selten auftreten. Dieser datengesteuerte Ansatz zur Kapazitätsplanung reduziert Verschwendung und hält gleichzeitig die Service-Level-Ziele ein. Regelmäßige Überprüfungen der Auslastung identifizieren Möglichkeiten zur Neuverteilung von Ressourcen oder zur Anpassung der Kapazität, die Budget für neue Initiativen freisetzen.
Implementierungs-Roadmap: Vom Pilotprojekt zur Produktion
Die erfolgreiche Implementierung einer KI-Infrastruktur folgt strukturierten Phasen, die die Fähigkeiten schrittweise aufbauen und gleichzeitig Risiken bei jedem Schritt managen. Dieser Roadmap-Ansatz ermöglicht es Organisationen, Ansätze zu validieren, bevor sie große Verpflichtungen eingehen, die Budgets entleeren könnten. Eine intelligente Implementierung reduziert sowohl technische als auch finanzielle Risiken.
Die Pilotphase etabliert eine Proof-of-Concept-Infrastruktur mit minimalen Hardware-Investitionen, die die technische Machbarkeit beweisen, ohne Budgets zu sprengen. Organisationen implementieren Single-Node- oder Small-Cluster-Konfigurationen, um KI-Workflows und Leistungsmerkmale unter realistischen Bedingungen zu validieren. Diese Phase konzentriert sich auf die technische Machbarkeit und grundlegende Betriebsverfahren, anstatt auf Produktionsmaßstäbe oder Hochverfügbarkeitsfunktionen. Erfolgskennzahlen umfassen erfolgreiches Modelltraining und Inferenz-Ausführung, anstatt Leistungsbenchmarks, die später wichtig werden.
Produktionsbereitschaftsphasen fügen Enterprise-Funktionen wie hohe Verfügbarkeit, Backup-Systeme, Überwachungsinfrastruktur und Sicherheitskontrollen hinzu, die Compliance-Teams fordern. Diese Phasen erfordern substantialere Hardware-Investitionen, bauen aber auf bewährten architektonischen Grundlagen auf, die in den Pilotphasen etabliert wurden. Organisationen können basierend auf dem tatsächlichen Bedarf schrittweise skalieren, anstatt auf theoretische Projektionen, wodurch das finanzielle Risiko reduziert und gleichzeitig das operative Vertrauen durch praktische Erfahrung aufgebaut wird.
Skalierungsüberlegungen und Wachstumsplanung
Skalierungsstrategien für die Infrastruktur müssen sowohl ein vorhersehbares Wachstum als auch unerwartete Nachfragespitzen berücksichtigen, die immer im ungünstigsten Moment aufzutreten scheinen. Modulare Architekturen ermöglichen die Kapazitätserweiterung durch standardisierte Hardware-Ergänzungen anstelle kompletter Systemauswechslungen, die bestehende Investitionen verschwenden würden. Dieser Ansatz schützt anfängliche Investitionen und bietet gleichzeitig Flexibilität für Wachstum, da die KI-Akzeptanz im gesamten Unternehmen zunimmt.
Multi-Tenant-Infrastrukturdesigns unterstützen mehrere KI-Projekte und Teams, ohne separate Hardware-Bereitstellungen für jede Initiative zu benötigen. Eine ordnungsgemäße Ressourcenisolierung und Workload-Scheduling gewährleisten eine gerechte Ressourcenverteilung und maximieren gleichzeitig die Hardware-Auslastung über Projekte hinweg. Diese Designs reduzieren die Infrastrukturkosten pro Projekt und erhalten gleichzeitig die operative Unabhängigkeit zwischen verschiedenen KI-Initiativen, die möglicherweise widersprüchliche Anforderungen haben.
Agentic AI Systeme und autonome Infrastruktur
Agentic AI-Systeme stellen die nächste Evolution in der Bereitstellung von Enterprise AI dar. Sie umfassen autonome Agenten, die zu mehrstufigem Denken und Handlungsausführung fähig sind, was weit über einfache Chatbots hinausgeht. Diese Systeme erfordern spezialisierte Infrastrukturkapazitäten, um langlaufende Prozesse und komplexe Interaktionsmuster zu unterstützen. Die Infrastrukturanforderungen unterscheiden sich erheblich von traditionellen Batch-ML-Workloads.
Die lokale Bereitstellung von Agentic AI-Systemen bietet erhebliche Vorteile gegenüber Cloud-basierten Alternativen, die offensichtlich werden, sobald man die operativen Anforderungen berücksichtigt. Autonome Agenten erfordern oft kontinuierlichen Betrieb und Entscheidungsfindung in Echtzeit, was Netzwerk-Latenz und Konnektivitätsabhängigkeiten für geschäftskritische Prozesse problematisch macht. On-Premises Agentic AI-Infrastruktur gewährleistet einen zuverlässigen Betrieb und sofortige Reaktionszeiten für zeitkritische Geschäftsprozesse, die keine Cloud-Ausfälle oder Netzwerk-Hicksen tolerieren können.
Die Infrastrukturanforderungen für agentische KI unterscheiden sich von traditionellen Machine-Learning-Workloads auf eine Weise, die Teams überrascht, die an Batch-Verarbeitungsmodelle gewöhnt sind. Diese Systeme benötigen persistente Zustandsverwaltung, komplexe Workflow-Orchestrierung und Integrationsfähigkeiten mit Geschäftssystemen und externen Diensten. Die Infrastruktur muss sowohl intensive Rechenphasen für die Argumentation als auch leichte Betriebsphasen für die Überwachung und Kommunikation mit anderen Systemen unterstützen.
Autonome Operationen und Selbstverwaltung
Fortschrittliche Agentic AI-Infrastruktur integriert Selbstverwaltungsfähigkeiten, die den Betriebsaufwand reduzieren und gleichzeitig die Systemzuverlässigkeit verbessern. Diese Systeme können ihre eigene Leistung überwachen, Anomalien erkennen und Korrekturmaßnahmen ohne menschliches Eingreifen während des Routinebetriebs einleiten. Dieses autonome Betriebsmodell reduziert die Gesamtbetriebskosten und verbessert gleichzeitig die Systemzuverlässigkeit und -verfügbarkeit über das hinaus, was manuelle Operationen erreichen können.
Die Ressourcenoptimierung wird in Agentic AI-Umgebungen, in denen Systeme ihre eigene Ressourcenallokation dynamisch an Workload-Anforderungen in Echtzeit anpassen können, ausgefeilter. Diese Selbstoptimierungsfunktion maximiert die Infrastruktureffizienz und hält gleichzeitig Leistungsstandards für kritische Geschäftsprozesse aufrecht. Das System lernt Nutzungsmuster und optimiert sich kontinuierlich, anstatt sich auf statische Konfigurationen zu verlassen, die veraltet sind.
Daten-Governance und Sicherheit bei lokaler KI-Bereitstellung
Daten-Governance-Frameworks für die KI-Infrastruktur müssen sowohl traditionelle Datenmanagement-Anforderungen als auch KI-spezifische Herausforderungen wie Modell-Lineage, Herkunft der Trainingsdaten und algorithmische Verantwortlichkeit adressieren. Die lokale Bereitstellung bietet erweiterte Kontrollmöglichkeiten zur Implementierung umfassender Governance-Programme, die sowohl Auditoren als auch Regulierungsbehörden zufriedenstellen. Die Kontrollvorteile werden entscheidend, wenn es um sensible Geschäftsdaten geht.
Sicherheitsarchitekturen für die lokale KI-Bereitstellung können Defense-in-Depth-Strategien mit mehreren Isolationsschichten implementieren, die Cloud-Umgebungen nicht bieten können. Die Netzwerksegmentierung trennt KI-Workloads von allgemeinen Geschäftsnetzwerken, während die notwendige Konnektivität für den Datenzugriff und die Systemintegration aufrechterhalten wird. Dieser Ansatz reduziert Angriffsflächen und bewahrt gleichzeitig die Betriebsfunktionalität, die Geschäftsanwender benötigen, um ihre Aufgaben zu erledigen.
Compliance-Automatisierung wird in lokalen Umgebungen, in denen Organisationen alle Systemkomponenten kontrollieren, ohne von Drittanbieter-Cloud-Anbietern abhängig zu sein, machbarer. Automatisierte Compliance-Überwachung, Audit-Logging und Richtliniendurchsetzung können ohne Abhängigkeit von Cloud-Anbieter-Compliance-Zertifizierungen implementiert werden, die möglicherweise nicht den spezifischen regulatorischen Anforderungen entsprechen. Diese Kontrolle erweist sich als unerlässlich für Organisationen, die strengen regulatorischen Anforderungen unterliegen, die reale Strafen für Nicht-Compliance nach sich ziehen.
Anforderungen an Datenresidenz und -hoheit
Die lokale KI-Bereitstellung adressiert Anforderungen an die Datenresidenz, die einschränken, wo sensible Informationen basierend auf Rechtsordnungen und regulatorischen Rahmenbedingungen verarbeitet oder gespeichert werden dürfen. Organisationen können geografische Kontrollen implementieren und sicherstellen, dass Daten genehmigte Grenzen ohne Vertrauen auf Cloud-Anbieter-Zusicherungen niemals verlassen. Diese Fähigkeit erweist sich als unerlässlich für Regierungsstellen, Gesundheitsorganisationen und multinationale Unternehmen, die unter mehreren regulatorischen Jurisdiktionen mit widersprüchlichen Anforderungen tätig sind.
Verschlüsselungs- und Schlüsselverwaltungssysteme in lokalen Bereitstellungen bieten zusätzliche Sicherheitsebenen, die in Cloud-Umgebungen nicht verfügbar sind, wo Sie die Infrastruktur mit anderen Mietern teilen. Organisationen können Hardware-Sicherheitsmodule, kundenspezifische Verschlüsselungsschemata und luftgetrennte Schlüsselverwaltungssysteme implementieren, die die Cloud-Sicherheitsfunktionen per Design übertreffen. Diese erweiterten Sicherheitsfunktionen rechtfertigen oft die Kosten der lokalen Bereitstellung für sicherheitsbewusste Organisationen, die geteilte Infrastrukturrisiken nicht akzeptieren können.
ROI-Messrahmen für AI Infrastrukturinvestitionen
Die Messung des ROI für die KI-Infrastruktur erfordert Frameworks, die sowohl direkte Kosteneinsparungen als auch indirekte Wertschöpfung erfassen, die traditionelle IT-ROI-Modelle gänzlich übersehen. Standard-IT-ROI-Modelle unterschätzen oft die Vorteile der KI-Infrastruktur, die sich über mehrere Geschäftsfunktionen und operative Bereiche erstrecken. Die Muster der Wertschöpfung unterscheiden sich erheblich von traditionellen Infrastrukturinvestitionen.
Direkte Kostenvergleiche sollten Berechnungen der Gesamtbetriebskosten (TCO) umfassen, die operative Ausgaben, Wartungskosten und Upgrade-Zyklen über realistische Zeiträume berücksichtigen. Diese Berechnungen müssen über die anfängliche Hardwarebeschaffung hinausgehen und Stromverbrauch, Einrichtungskosten und Personalbedarf umfassen, die sich im Laufe der Zeit ansammeln. Eine genaue TCO-Analyse ermöglicht einen fairen Vergleich zwischen lokalen und Cloud-Bereitstellungsoptionen ohne versteckte Überraschungen, die später auftauchen.
Die indirekte Wertschöpfung aus der KI-Infrastruktur umfasst eine verbesserte Entwicklungsgeschwindigkeit, eine verkürzte Markteinführungszeit für KI-Anwendungen und verbesserte Innovationsfähigkeiten, die neue Geschäftsmodelle ermöglichen. Diese Vorteile übertreffen oft die direkten Kosteneinsparungen, erfordern jedoch sorgfältige Messmethoden, um sie für die Berichterstattung an die Geschäftsleitung genau zu quantifizieren. Organisationen sollten vor der Infrastrukturbereitstellung Basislinienmetriken festlegen, um Verbesserungen genau zu messen, anstatt sich auf Schätzungen oder Annahmen zu verlassen.
Leistungsmetriken und Erfolgsindikatoren
Infrastruktur-Performance-Metriken müssen auf die Anforderungen der KI-Anwendung abgestimmt sein und nicht auf traditionelle IT-Metriken, die das für KI-Workloads wirklich Wichtige übersehen. Durchsatzmessungen, Latenzcharakteristika und Ressourcenauslastungsmuster, die spezifisch für KI-Workloads sind, liefern relevantere Leistungsindikatoren als generische Servermetriken. Diese spezialisierten Messungen leiten Optimierungsentscheidungen und Kapazitätsplanungsaktivitäten, die sowohl die Leistung als auch die Kosteneffizienz verbessern.
Business Impact Metriken verbinden Infrastrukturleistung mit Unternehmensergebnissen, die Führungskräfte über technische Spezifikationen hinaus interessieren. Metriken wie Modellbereitstellungshäufigkeit, Experimentiergeschwindigkeit und Zuverlässigkeit von Produktionssystemen zeigen, wie Infrastrukturfähigkeiten in Geschäftswert umgesetzt werden. Diese Messungen rechtfertigen kontinuierliche Investitionen und leiten zukünftige Infrastrukturplanungsentscheidungen, die sich an Geschäftsprioritäten und nicht an technischen Präferenzen orientieren.
Häufig gestellte Fragen
Was sind die Hauptkostenunterschiede zwischen Cloud- und On-Premises-KI-Infrastruktur?
Die On-Premises-KI-Infrastruktur erfordert in der Regel höhere anfängliche Kapitalinvestitionen, liefert aber vorhersehbare Betriebskosten durch Hardware-Abschreibungsmodelle, die Finanzteams planen können. Cloud-Bereitstellungen bieten geringere Anfangskosten, verursachen aber variable Betriebskosten, die bei Skalierung und Nutzungsmustern schnell eskalieren können. Berechnungen der Gesamtbetriebskosten sollten Datenübertragungsgebühren, Speicherkosten und Rechengebühren über Zeiträume von 3-5 Jahren berücksichtigen, um einen genauen Vergleich zu ermöglichen. Die meisten Unternehmen stellen fest, dass Cloud-Kosten bei Produktionsgröße unerschwinglich werden, insbesondere für GPU-intensive Workloads, die kontinuierlich laufen.
Wie lange dauert es typischerweise, eine produktionsreife KI-Infrastruktur bereitzustellen?
Die Implementierungszeiten für KI-Produktionsinfrastrukturen reichen von 3-6 Monaten für standardisierte Konfigurationen bis zu 12-18 Monaten für komplexe kundenspezifische Architekturen, die umfangreiche Integrationsarbeiten erfordern. Der Zeitrahmen hängt von den Lieferzeiten der Hardware, den Anforderungen an die Anlagenvorbereitung, der Komplexität der Softwareintegration und der Bereitschaft des Teams ab, die neuen Systeme zu betreiben. Organisationen, die validierte Referenzarchitekturen wie die Dell AI Factory verwenden, können die Bereitstellungszeit durch vorab getestete Konfigurationen und professionellen Service-Support, der häufige Integrationsfallen eliminiert, erheblich verkürzen.
Welche Sicherheitsvorteile bietet die lokale KI-Bereitstellung gegenüber Cloud-Lösungen?
Die lokale KI-Bereitstellung eliminiert externe Netzwerkabhängigkeiten, bietet vollständige Datenresidenzkontrolle und ermöglicht kundenspezifische Sicherheitsarchitekturen, die auf spezifische organisatorische Anforderungen zugeschnitten sind und von Cloud-Anbietern nicht erreicht werden können. Organisationen können air-gapped Umgebungen, kundenspezifische Verschlüsselungsschemata und Netzwerkisolationsstrategien implementieren, die in gemeinsam genutzten Cloud-Umgebungen nicht verfügbar sind, wo Sie im Wesentlichen anderen Mietern und den Sicherheitspraktiken des Cloud-Anbieters vertrauen müssen. Dieses Maß an Sicherheitskontrolle erweist sich als unerlässlich für stark regulierte Branchen und sensible Regierungsanwendungen, bei denen Datenlecks schwerwiegende Folgen haben.
Wie stellen Organisationen eine angemessene GPU-Rechenkapazität für KI-Workloads sicher?
Die GPU-Kapazitätsplanung erfordert ein Workload-Profiling, um Spitzen- und durchschnittliche Auslastungsmuster über verschiedene KI-Anwendungen hinweg zu verstehen, anstatt auf theoretische Maxima zu raten. Organisationen sollten tatsächliche Nutzungsmuster aus Pilotbereitstellungen überwachen, anstatt theoretische Maxima, die in der Praxis selten auftreten, und Ressourcen-Pooling implementieren, um GPU-Kapazität effizient über mehrere Projekte hinweg zu teilen. Moderne Infrastrukturplattformen bieten Workload-Scheduling- und Ressourcenallokationsfunktionen, die die GPU-Auslastung optimieren und gleichzeitig die Leistungsisolierung zwischen Anwendungen aufrechterhalten, die um Ressourcen konkurrieren.
Welche Rolle spielt die Vernetzung für die Leistung der KI-Infrastruktur?
Hochleistungsnetzwerke sind entscheidend für verteiltes KI-Training, Datenübertragung zwischen Speicher- und Rechenressourcen und Multi-Node-Inferencing, das über Einzelserver-Bereitstellungen hinausgeht. KI-Workloads erfordern oft eine Konnektivität mit geringer Latenz und hoher Bandbreite, die die Fähigkeiten traditioneller Unternehmensnetzwerke, die für Büroanwendungen und Web-Browsing konzipiert sind, übertrifft. Spezialisierte Netzwerkstrukturen wie InfiniBand oder Hochgeschwindigkeits-Ethernet bieten die Leistungsmerkmale, die für anspruchsvolle KI-Anwendungen erforderlich sind, die kontinuierlich große Datenmengen und Modellparameter zwischen Knoten verschieben.
Wie verwalten Organisationen die Bereitstellung und Versionierung von KI-Modellen in lokalen Umgebungen?
Die Modellbereitstellung und -versionierung erfordert MLOps-Plattformen, die automatisierte Pipeline-Verwaltung, Versionskontrolle und Rollback-Funktionen bieten, die speziell für KI-Workloads und nicht für herkömmliche Softwarebereitstellungstools entwickelt wurden. Lokale Bereitstellungen können diese Plattformen mit Tools wie Kubeflow, MLflow oder kommerziellen Alternativen, die On-Premises bereitgestellt werden, mit voller Kontrolle über die Bereitstellungspipeline implementieren. Der Schlüssel liegt in der Etablierung systematischer Prozesse für die Modellvalidierung, die Bereitstellungsfreigabe und die Produktionsüberwachung, die eine zuverlässige KI-Dienstbereitstellung gewährleisten und gleichzeitig Audit-Trails für Compliance-Anforderungen aufrechterhalten.
Welche Wartungs- und Supportüberlegungen gelten für On-Premises-KI-Infrastrukturen?
Die On-Premises-KI-Infrastruktur erfordert spezialisiertes Wartungs-Know-how für GPU-Systeme, Hochleistungsspeicher und KI-Softwareplattformen, das sich erheblich von der traditionellen IT-Infrastrukturwartung unterscheidet. Unternehmen sollten Hardware-Wartungsverträge, Software-Supportvereinbarungen und interne Team-Schulungen planen, um die Systemzuverlässigkeit zu gewährleisten, ohne bei jedem Problem auf externe Anbieter angewiesen zu sein. Die Komplexität der KI-Infrastruktur rechtfertigt oft Partnerschaften mit professionellen Dienstleistern, um interne Kapazitäten während der anfänglichen Bereitstellungs- und Betriebsphasen zu ergänzen und gleichzeitig interne Expertise aufzubauen.
Wie können Unternehmen lokale KI-Infrastrukturen mit bestehenden Unternehmenssystemen integrieren?
Die Unternehmensintegration erfordert eine sorgfältige Planung für Netzwerkkonnektivität, Authentifizierungssysteme, Datenzugriffsmuster und Anwendungsschnittstellen, die KI-Fähigkeiten mit bestehenden Geschäftsprozessen verbinden. Moderne KI-Plattformen bieten APIs und Integrations-Frameworks, die die Verbindung mit Unternehmensdatenquellen, Geschäftsanwendungen und Betriebssystemen erleichtern, ohne komplette Systemwechsel zu erfordern. Die Integrationsarchitektur sollte Sicherheitsgrenzen aufrechterhalten und gleichzeitig den notwendigen Datenfluss und die Systeminteraktion ermöglichen, die Geschäftsanwender benötigen, um KI-Erkenntnisse in ihre täglichen Workflows einzubinden.
Welche Überlegungen zur Sicherung und Wiederherstellung im Katastrophenfall gelten für die KI-Infrastruktur?
KI-Infrastruktur-Backup-Strategien müssen große Modelldateien, Trainingsdatensätze und Konfigurationszustände berücksichtigen, die traditionelle Backup-Anforderungen um Größenordnungen übertreffen. Wiederherstellungsverfahren sollten kritische Inferenzdienste priorisieren und längere Wiederherstellungszeiten für Trainingsinfrastrukturen einplanen, die bei Bedarf wieder aufgebaut werden können. Viele Unternehmen implementieren gestaffelte Wiederherstellungsstrategien, die bei Katastrophenfällen Produktionsinferenzfähigkeiten gegenüber Entwicklungs- und Trainingssystemen priorisieren, da sie erkennen, dass die Geschäftskontinuität eher vom Betrieb von Modellen als vom sofortigen Training neuer abhängt.
Wie messen Unternehmen den Erfolg ihrer KI-Infrastrukturinvestitionen?
Die Erfolgsmessung erfordert sowohl technische als auch geschäftliche Metriken, die den Wert der Infrastruktur über einfache Verfügbarkeits- und Nutzungsstatistiken hinaus aufzeigen. Technische Metriken umfassen Systemverfügbarkeit, Leistungsbenchmarks und Ressourcenauslastungseffizienz, die zeigen, dass die Infrastruktur wie vorgesehen funktioniert. Geschäftsmetriken konzentrieren sich auf die Bereitstellungsgeschwindigkeit von KI-Anwendungen, Verbesserungen der Entwicklerproduktivität und Reduzierung der Betriebskosten, die technische Fähigkeiten in Geschäftsergebnisse umsetzen. Die regelmäßige Bewertung dieser Metriken leitet Optimierungsentscheidungen und rechtfertigt weitere Infrastrukturinvestitionen gegenüber Führungskräften, denen der Geschäftseinfluss wichtiger ist als technische Spezifikationen.
Fazit
Infrastruktur-First-Ansätze für die Enterprise AI stellen einen grundlegenden Wandel von reaktiven zu proaktiven Bereitstellungsstrategien dar, die in der realen Welt tatsächlich funktionieren. Organisationen, die robuste Grundlagen gegenüber schnellen Erfolgen priorisieren, positionieren sich für nachhaltigen KI-Erfolg über mehrere Anwendungsfälle und Geschäftsfunktionen hinweg. Die Beweise zeigen klar, dass eine durchdachte Infrastrukturplanung langfristige Kosten senkt und gleichzeitig die KI-Akzeptanz im gesamten Unternehmen beschleunigt. Man kann keine dauerhaften KI-Fähigkeiten auf wackeligen Grundlagen aufbauen.
Lokale KI-Bereitstellungsstrategien bieten Unternehmen überzeugende Vorteile, die Kostentransparenz, verbesserte Sicherheit und operative Kontrolle suchen, die Cloud-Anbieter einfach nicht liefern können. Während Cloud-Lösungen Flexibilität für Experimente und Pilotprojekte bieten, profitieren KI-Implementierungen im Produktionsmaßstab oft von On-Premises-Infrastruktur, die konsistente Leistung und vorhersehbare Wirtschaftlichkeit ohne unerwartete Rechnungen oder Dienstunterbrechungen liefert. Der Schlüssel zum Erfolg liegt darin, Infrastrukturansätze an spezifische organisatorische Anforderungen anzupassen, anstatt blinden Branchentrends oder Anbieterempfehlungen zu folgen. Ihre heutigen Infrastrukturentscheidungen bestimmen Ihre KI-Fähigkeiten von morgen.
Zuletzt aktualisiert: Juni 2026
Blck Alpaca ist eine KI-Marketing-Automatisierungsagentur mit Sitz in Wien, spezialisiert auf datengetriebenes Marketing, maßgeschneiderte KI-Agenten und Enterprise-Workflow-Automatisierung für Unternehmen im DACH-Raum.
Weitere Artikel
Entdecke mehr Insights aus unserem Blog



{kind=link}
{kind=link}
{kind=link}
Keine Insights verpassen
Abonniere unseren Newsletter und erhalte AI & Marketing Trends direkt in dein Postfach.