Enterprise AI Infrastructure: Tackle 2026 Challenges

Infrastructure-First Enterprise AI: How Local Deployment Cuts Costs and Closes the Execution Gap
Enterprise AI adoption rates are through the roof, but execution? That's where things fall apart. Organizations pour money into AI strategy and proof-of-concepts, then get stuck in what I call "pilot purgatory" — unable to move beyond experiments into production systems that actually deliver measurable business value.
This guide shows how infrastructure-first approaches to enterprise AI infrastructure transform cost structures, accelerate time-to-value, and bridge the gap between AI ambition and operational reality through local deployment strategies. We'll explore why starting with solid foundations beats chasing shiny AI features every single time.
Definition: Enterprise AI Infrastructure
Enterprise AI infrastructure comprises the integrated hardware, software, and operational framework required to deploy, manage, and scale Artificial Intelligence workloads in production environments. This includes compute resources with AI accelerators, high-performance storage systems, networking fabric optimized for ML workloads, and the management layer that orchestrates these components. Modern enterprise AI infrastructure prioritizes flexibility between cloud and on-premises deployment while maintaining data governance, security controls, and predictable cost structures.
Table of Contents
- The Enterprise AI Execution Gap: Why Most Projects Fail
- Infrastructure-First Strategy: Building from the Foundation Up
- Cloud Cost Reality: Why Enterprise AI Bills Explode
- Local AI Deployment: Control, Cost, and Compliance Advantages
- Dell AI Factory: Modern On-Premises AI Infrastructure
- Cost Optimization Strategies for AI Infrastructure
- Implementation Roadmap: From Pilot to Production
- Agentic AI Systems and Autonomous Infrastructure
- Data Governance and Security in Local AI Deployment
- ROI Measurement Framework for AI Infrastructure Investment
- Frequently Asked Questions
- Conclusion
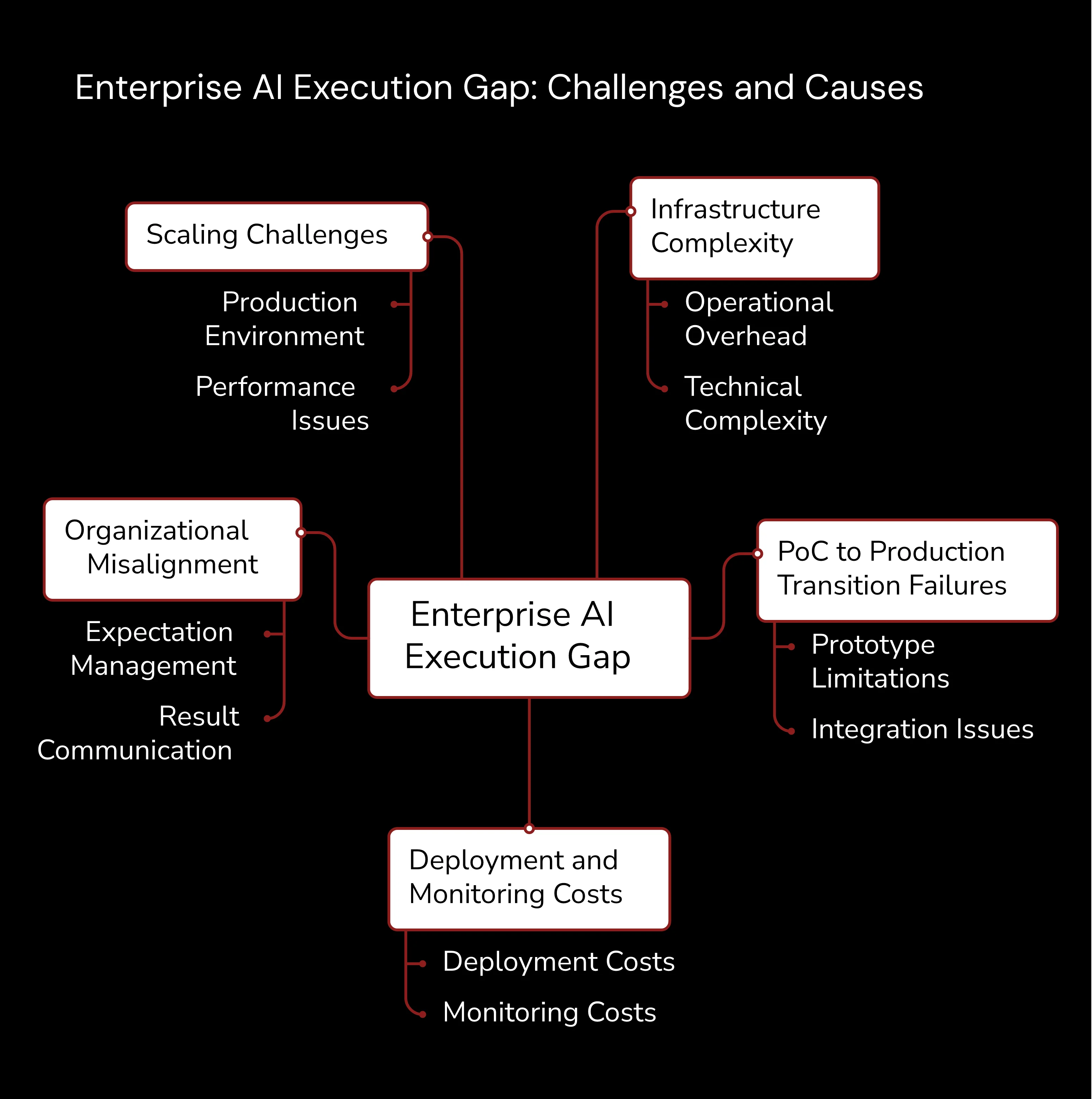
The Enterprise AI Execution Gap: Why Most Projects Fail
The enterprise AI execution gap represents that painful chasm between what organizations want to achieve with AI and what actually happens in production. Multiple factors contribute to this persistent challenge facing technology leaders across industries. The pattern repeats itself everywhere: big promises, bigger budgets, and disappointing results.
Infrastructure complexity stands as the primary killer of AI execution success. Organizations consistently underestimate the operational overhead required to deploy, monitor, and maintain AI systems at scale. Development teams build proof-of-concepts on laptops or limited cloud instances, then face reality shock when production demands require enterprise-grade infrastructure with high availability, security controls, and performance guarantees. The gap between experimental environments and production requirements often proves insurmountable without significant additional investment. That's where most projects die.
58% of enterprises
exceeded their AI infrastructure estimates by more than 40%, creating budget overruns that force project delays or cancellations (Medha Cloud, 2026).
Skills and resource constraints amplify execution challenges in ways that catch executives off guard. AI projects demand specialized expertise in machine learning operations, infrastructure management, and data engineering simultaneously. Most organizations lack the cross-functional teams needed to bridge data science capabilities with production engineering requirements. This skills gap creates bottlenecks that extend project timelines and increase the likelihood of technical debt accumulation in AI systems. You can't just hire your way out of this problem overnight.
Governance and compliance requirements add another layer of complexity to enterprise AI execution that surfaces at the worst possible moment. Organizations must implement data lineage tracking, model versioning, audit trails, and Regulatory Compliance frameworks before AI systems can process sensitive business data. These requirements often surface late in project lifecycles, forcing teams to retrofit governance capabilities into systems designed without these constraints. The resulting technical debt and architectural compromises frequently doom projects to perpetual pilot status.
Infrastructure-First Strategy: Building from the Foundation Up
Infrastructure-first approaches to enterprise AI flip traditional Implementation Strategies by establishing production-ready foundations before developing specific AI applications. This methodology addresses root causes of AI execution failures through systematic capability building. Think of it as constructing the highway system before planning the traffic routes.
The infrastructure-first model begins with comprehensive compute resource planning that actually considers real workloads. Organizations assess their AI requirements across training, inference, and data processing tasks to determine optimal hardware configurations. This includes selecting appropriate GPU accelerators, planning memory and storage capacity, and designing networking architectures that support high-throughput AI operations. By establishing robust compute foundations first, teams avoid performance bottlenecks that plague reactive infrastructure approaches.
Storage and data platform design receives equal priority in infrastructure-first strategies because data access patterns make or break AI performance. AI applications demand high-performance access to large datasets, requiring storage systems optimized for both throughput and IOPS. Modern enterprise AI infrastructure incorporates NVMe storage tiers, distributed file systems, and data lake architectures that support both structured and unstructured data access patterns. This foundation enables data scientists to focus on model development rather than wrestling with data access limitations that kill productivity.
Platform Standardization Benefits
Standardized AI platforms reduce operational complexity while improving resource utilization efficiency across the board. Organizations deploy consistent toolchains, runtime environments, and management interfaces across all AI projects. This standardization accelerates developer onboarding, simplifies troubleshooting, and enables resource sharing between projects. Teams spend less time on infrastructure configuration and more time on value-creating AI development activities. That's where the real magic happens.
Container orchestration and MLOps pipelines form core components of standardized AI platforms that actually work in production. Kubernetes provides workload scheduling and resource management capabilities essential for multi-tenant AI environments. MLOps pipelines automate model training, validation, deployment, and monitoring workflows, reducing manual intervention and improving system reliability. These platform capabilities transform AI development from artisanal craft to engineered discipline with repeatable processes and predictable outcomes.
Cloud Cost Reality: Why Enterprise AI Bills Explode
Cloud cost optimization becomes critical as AI workloads scale beyond experimental phases into real business applications. Understanding cloud pricing models and cost drivers enables organizations to Make ↗ informed infrastructure decisions. The sticker shock often comes too late to change course.
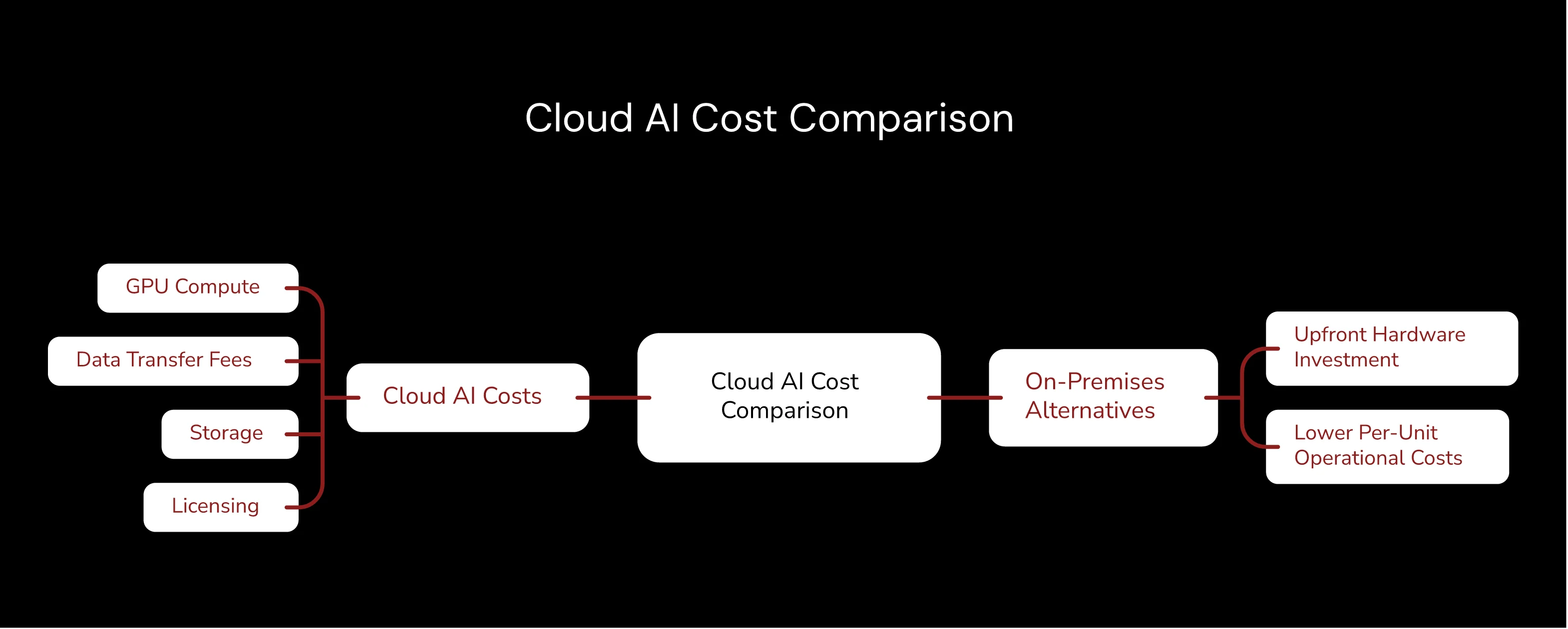
GPU compute costs represent the largest component of cloud AI expenses, and they escalate faster than most finance teams expect. Major cloud providers charge premium rates for AI-optimized instances, with costs climbing rapidly as workloads require more powerful accelerators. Training large language models or computer vision systems can consume thousands of dollars in compute credits within hours. Organizations frequently underestimate these costs during pilot phases, leading to budget shocks when scaling to production workloads.
Cost Category | Typical Cloud Impact | On-Premises Alternative |
|---|---|---|
GPU Compute | Variable hourly rates | Fixed amortized cost |
Data Transfer | Egress charges accumulate | Local network included |
Storage | Per-GB monthly fees | Bulk capacity investment |
API Calls | Per-request billing | Unlimited local inference |
Management | Service fees and markups | Internal operational control |
Data movement costs create additional financial pressure in cloud environments that catches teams off guard. AI applications often require frequent data transfers between storage systems, compute resources, and external services. Cloud providers charge significant egress fees for data movement, especially when transferring large datasets or model artifacts. These costs compound as AI systems scale and generate more data products. What starts as pocket change becomes real money fast.
The unpredictability of cloud AI costs challenges financial planning and budget control in ways that keep CFOs awake at night. Usage-based pricing models make it difficult to forecast monthly expenses, especially for experimental or seasonal AI workloads. Organizations frequently experience cost spikes during model training phases or data processing cycles, leading to budget overruns and executive scrutiny of AI investments. Finance teams hate surprises, and cloud AI costs deliver plenty of them.
Local AI Deployment: Control, Cost, and Compliance Advantages
Local AI deployment offers compelling advantages for enterprise organizations seeking predictable costs and enhanced control over their AI infrastructure. On-premises solutions address many limitations inherent in cloud-based AI platforms. The benefits become obvious once you factor in long-term operational costs and security requirements.
Cost predictability represents the most immediate benefit of local AI deployment that finance teams actually appreciate. Organizations invest in hardware assets with known depreciation schedules rather than variable operational expenses that fluctuate wildly. This capital expenditure model enables accurate long-term cost forecasting and eliminates unexpected usage spikes that plague cloud deployments. Finance teams appreciate the budget certainty that local infrastructure provides, especially when planning multi-year AI initiatives.
"The real value of on-premises AI isn't just cost control — it's the architectural freedom to build exactly what your business requires."
Data sovereignty and regulatory compliance favor local deployment strategies in ways that cloud providers simply cannot match. Organizations maintain complete control over data location, access patterns, and retention policies without relying on third-party compliance certifications. This control proves essential for industries subject to strict regulatory requirements like healthcare, financial services, and government sectors. Local deployment eliminates concerns about data residency violations and third-party access risks inherent in cloud services.
Performance optimization reaches higher levels in local deployments where organizations control the entire infrastructure stack from silicon to software. Custom networking configurations, specialized storage systems, and optimized compute clusters can be tuned specifically for AI workload requirements. This level of optimization often proves impossible in multi-tenant cloud environments where infrastructure resources are shared across multiple customers with competing demands.
Privacy and Security Benefits
Local AI deployment strengthens security postures by eliminating external network dependencies and third-party access risks that plague cloud environments. Sensitive business data remains within organizational boundaries throughout the AI pipeline, from raw data ingestion through model training and inference deployment. This approach satisfies strict security requirements without compromising AI capability or performance. Security teams sleep better knowing exactly where their data lives.
Network isolation capabilities in local deployments exceed cloud alternatives by orders of magnitude. Organizations can implement air-gapped AI environments for highly sensitive applications or deploy network segmentation strategies that isolate AI workloads from general business networks. These security architectures provide defense-in-depth protection while maintaining operational flexibility that cloud shared responsibility models cannot deliver.
Dell AI Factory: Modern On-Premises AI Infrastructure
Dell AI Factory represents a comprehensive approach to enterprise AI infrastructure that combines hardware, software, and services into integrated solutions that actually work together. This platform addresses common challenges in AI deployment through validated reference architectures and professional services support. The integrated approach eliminates the integration headaches that kill so many AI projects.
The Dell AI Factory architecture incorporates PowerEdge servers optimized for AI workloads, featuring NVIDIA, Intel, and AMD accelerators configured for maximum performance out of the box. These systems include high-bandwidth memory, NVMe storage arrays, and specialized networking fabric designed to support demanding AI applications. The integrated approach eliminates compatibility concerns and reduces deployment complexity compared to component-by-component infrastructure building that often leads to finger-pointing between vendors.
Recent announcements at Dell Technologies World 2026 introduced Dell Deskside Agentic AI, enabling organizations to run autonomous AI agents locally without cloud dependencies or ongoing subscription fees. This capability brings agentic AI systems into enterprise environments while maintaining data privacy and security controls that compliance teams demand. The solution demonstrates how on-premises AI infrastructure can support advanced AI capabilities traditionally associated with cloud platforms.
Ecosystem Partnerships and Integration
Dell's AI Ecosystem Program validates third-party software and AI models for compatibility with Dell AI Factory infrastructure, eliminating the integration risks that plague custom deployments. This validation process reduces integration risks and accelerates deployment timelines by providing pre-tested combinations of hardware and software components. Partners include major AI Platform vendors, model providers, and specialized AI application developers who've done the hard work of testing combinations.
Strategic partnerships with OpenAI ↗, NVIDIA, and other AI leaders enable on-premises deployment of frontier AI models through Dell infrastructure without sacrificing cutting-edge capabilities. These partnerships bring cloud-native AI capabilities into enterprise data centers while maintaining local control over data and operations. The approach demonstrates how on-premises infrastructure can access advanced AI technologies without sacrificing security or governance requirements that matter to enterprise buyers.
Cost Optimization Strategies for AI Infrastructure
Effective cost optimization requires systematic approaches to AI infrastructure planning and resource management that go beyond simple budget cuts. Organizations must balance performance requirements with budget constraints while planning for future growth that won't break the bank. Smart optimization actually improves performance while reducing costs.
- Workload Analysis — Profile AI applications to understand compute, memory, and storage requirements across different operational phases
- Resource Pooling — Share infrastructure resources across multiple AI projects to improve utilization rates and reduce per-project costs
- Lifecycle Management — Plan hardware refresh cycles to align with technology advancement curves and depreciation schedules
- Energy Efficiency — Select power-efficient components and implement cooling strategies to minimize operational expenses
- Automation Investment — Deploy infrastructure automation tools to reduce manual operational overhead and improve system reliability
Resource rightsizing prevents overprovisioning while ensuring adequate performance for AI workloads that actually matter to the business. Organizations should monitor actual resource utilization patterns rather than relying on theoretical maximum requirements that rarely occur in practice. This data-driven approach to capacity planning reduces waste while maintaining service level objectives. Regular utilization reviews identify opportunities for resource reallocation or capacity adjustments that free up budget for new initiatives.
Implementation Roadmap: From Pilot to Production
Successful AI infrastructure implementation follows structured phases that build capability incrementally while managing risk at each step. This roadmap approach enables organizations to validate approaches before making large-scale commitments that could drain budgets. Smart implementation reduces both technical and financial risk.
The pilot phase establishes proof-of-concept infrastructure using minimal hardware investments that prove technical feasibility without breaking budgets. Organizations deploy single-node or small-cluster configurations to validate AI Workflows and performance characteristics under realistic conditions. This phase focuses on technical feasibility and basic operational procedures rather than production scale or high availability features. Success metrics include successful model training and inference execution rather than performance benchmarks that matter later.
Production readiness phases add enterprise capabilities like high availability, backup systems, monitoring infrastructure, and security controls that compliance teams demand. These phases require more substantial hardware investments but build on proven architectural foundations established during pilot phases. Organizations can scale incrementally based on actual demand rather than theoretical projections, reducing financial risk while building operational confidence through hands-on experience.
Scaling Considerations and Growth Planning
Infrastructure scaling strategies must accommodate both predictable growth and unexpected demand spikes that always seem to happen at the worst possible moment. Modular architectures enable capacity expansion through standardized hardware additions rather than complete system replacements that waste existing investments. This approach protects initial investments while providing growth flexibility as AI adoption increases across the organization.
Multi-tenant infrastructure designs support multiple AI projects and teams without requiring separate hardware deployments for each initiative. Proper resource isolation and workload scheduling ensure fair resource allocation while maximizing hardware utilization across projects. These designs reduce per-project infrastructure costs while maintaining operational independence between different AI initiatives that may have conflicting requirements.
Agentic AI Systems and Autonomous Infrastructure
Agentic AI systems represent the next evolution in enterprise AI deployment, featuring autonomous agents capable of multi-step reasoning and action execution that goes far beyond simple chatbots. These systems require specialized infrastructure capabilities to support long-running processes and complex interaction patterns. The infrastructure requirements differ significantly from traditional batch ML workloads.
Local deployment of agentic AI systems provides significant advantages over cloud-based alternatives that become obvious once you consider operational requirements. Autonomous agents often require continuous operation and real-time decision making, making network latency and connectivity dependencies problematic for business-critical processes. On-premises agentic AI infrastructure ensures reliable operation and immediate response times for time-sensitive business processes that cannot tolerate cloud outages or network hiccups.
Infrastructure requirements for agentic AI differ from traditional machine learning workloads in ways that surprise teams used to batch processing models. These systems need persistent state management, complex workflow orchestration, and integration capabilities with business systems and external services. The infrastructure must support both intensive compute phases for reasoning and lightweight operational phases for monitoring and communication with other systems.
Autonomous Operations and Self-Management
Advanced agentic AI infrastructure incorporates self-management capabilities that reduce operational overhead while improving system reliability. These systems can monitor their own performance, detect anomalies, and initiate corrective actions without human intervention during routine operations. This autonomous operation model reduces the total cost of ownership while improving system reliability and availability beyond what manual operations can achieve.
Resource optimization becomes more sophisticated in agentic AI environments where systems can dynamically adjust their own resource allocation based on workload demands in real-time. This self-tuning capability maximizes infrastructure efficiency while maintaining performance standards for critical business processes. The system learns usage patterns and optimizes itself continuously rather than relying on static configuration that becomes outdated.
Data Governance and Security in Local AI Deployment
Data governance frameworks for AI infrastructure must address both traditional data management requirements and AI-specific challenges like model lineage, training data provenance, and algorithmic accountability. Local deployment provides enhanced control capabilities for implementing comprehensive governance programs that satisfy both auditors and regulators. The control advantages become critical when dealing with sensitive business data.
Security architectures for local AI deployment can implement defense-in-depth strategies with multiple isolation layers that cloud environments cannot match. Network segmentation separates AI workloads from general business networks while maintaining necessary connectivity for data access and system integration. This approach reduces attack surfaces while preserving operational functionality that business users need to get their jobs done.
Compliance automation becomes more feasible in local environments where organizations control all system components without depending on third-party cloud providers. Automated compliance monitoring, audit logging, and policy enforcement can be implemented without dependence on cloud provider compliance certifications that may not meet specific regulatory requirements. This control proves essential for organizations subject to strict regulatory requirements that carry real penalties for non-compliance.
Data Residency and Sovereignty Requirements
Local AI deployment addresses data residency requirements that restrict where sensitive information can be processed or stored based on legal jurisdictions and regulatory frameworks. Organizations can implement geographic controls and ensure data never leaves approved boundaries without relying on cloud provider assurances. This capability proves essential for government entities, healthcare organizations, and multinational corporations operating under multiple regulatory jurisdictions with conflicting requirements.
Encryption and key management systems in local deployments provide additional security layers unavailable in cloud environments where you're sharing infrastructure with other tenants. Organizations can implement hardware security modules, custom encryption schemes, and air-gapped key management systems that exceed cloud security capabilities by design. These advanced security features often justify local deployment costs for security-conscious organizations that cannot accept shared infrastructure risks.
ROI Measurement Framework for AI Infrastructure Investment
ROI measurement for AI infrastructure requires frameworks that capture both direct cost savings and indirect value creation that traditional IT ROI models miss entirely. Standard IT ROI models often undervalue AI infrastructure benefits that span multiple business functions and operational areas. The value creation patterns differ significantly from traditional infrastructure investments.
Direct cost comparisons should include total cost of ownership calculations that factor in operational expenses, maintenance costs, and upgrade cycles over realistic timeframes. These calculations must extend beyond initial hardware acquisition to include power consumption, facilities costs, and personnel requirements that accumulate over time. Accurate TCO analysis enables fair comparison between local and cloud deployment options without hidden surprises that surface later.
Indirect value creation from AI infrastructure includes improved development velocity, reduced time-to-market for AI applications, and enhanced innovation capabilities that enable new business models. These benefits often exceed direct cost savings but require careful measurement methodologies to quantify accurately for executive reporting. Organizations should establish baseline metrics before infrastructure deployment to measure improvement accurately rather than relying on estimates or assumptions.
Performance Metrics and Success Indicators
Infrastructure performance metrics must align with AI application requirements rather than traditional IT metrics that miss what actually matters for AI workloads. Throughput measurements, latency characteristics, and resource utilization patterns specific to AI workloads provide more relevant performance indicators than generic server metrics. These specialized measurements guide optimization decisions and capacity planning activities that improve both performance and cost efficiency.
Business impact metrics connect infrastructure performance to organizational outcomes that executives care about beyond technical specifications. Metrics like model deployment frequency, experimentation velocity, and production system reliability demonstrate how infrastructure capabilities translate into business value. These measurements justify continued investment and guide future infrastructure planning decisions that align with business priorities rather than technical preferences.
Frequently Asked Questions
What are the main cost differences between cloud and on-premises AI infrastructure?
On-premises AI infrastructure typically requires higher upfront capital investment but delivers predictable operational costs through hardware depreciation models that finance teams can plan around. Cloud deployments offer lower initial costs but create variable operational expenses that can escalate quickly with scale and usage patterns. Total cost of ownership calculations should factor in data transfer fees, storage costs, and compute charges over 3-5 year periods to enable accurate comparison. Most organizations find that cloud costs become prohibitive at production scale, especially for GPU-intensive workloads that run continuously.
How long does it typically take to deploy production-ready AI infrastructure?
Production AI infrastructure deployment timelines range from 3-6 months for standardized configurations to 12-18 months for complex custom architectures that require extensive integration work. The timeline depends on hardware procurement lead times, facility preparation requirements, software integration complexity, and team readiness to operate the new systems. Organizations using validated reference architectures like Dell AI Factory can significantly reduce deployment time through pre-tested configurations and professional services support that eliminates common integration pitfalls.
What security advantages does local AI deployment provide over cloud solutions?
Local AI deployment eliminates external network dependencies, provides complete data residency control, and enables custom security architectures tailored to specific organizational requirements that cloud providers cannot match. Organizations can implement air-gapped environments, custom encryption schemes, and network isolation strategies not available in shared cloud environments where you're essentially trusting other tenants and the cloud provider's security practices. This level of security control proves essential for highly regulated industries and sensitive government applications where data breaches carry severe consequences.
How do organizations ensure adequate GPU compute capacity for AI workloads?
GPU capacity planning requires workload profiling to understand peak and average utilization patterns across different AI applications rather than guessing based on theoretical maximums. Organizations should monitor actual usage patterns from pilot deployments rather than theoretical maximums that rarely occur in practice, and implement resource pooling to share GPU capacity across multiple projects efficiently. Modern infrastructure platforms provide workload scheduling and resource allocation features that optimize GPU utilization while maintaining performance isolation between applications that compete for resources.
What role does networking play in AI infrastructure performance?
High-performance networking proves critical for distributed AI training, data movement between storage and compute resources, and multi-node inference serving that scales beyond single-server deployments. AI workloads often require low-latency, high-bandwidth connectivity that exceeds traditional enterprise network capabilities designed for office applications and web browsing. Specialized networking fabric like InfiniBand or high-speed Ethernet provides the performance characteristics needed for demanding AI applications that move large datasets and model parameters between nodes continuously.
How do organizations manage AI model deployment and versioning in local environments?
Model deployment and versioning requires MLOps platforms that provide automated pipeline management, version control, and rollback capabilities specifically designed for AI workloads rather than traditional software deployment tools. Local deployments can implement these platforms using tools like Kubeflow, MLflow, or commercial alternatives deployed on-premises with full control over the deployment pipeline. The key lies in establishing systematic processes for model validation, deployment approval, and production monitoring that ensure reliable AI service delivery while maintaining audit trails for compliance requirements.
What maintenance and support considerations apply to on-premises AI infrastructure?
On-premises AI infrastructure requires specialized maintenance expertise for GPU systems, high-performance storage, and AI software platforms that differ significantly from traditional IT infrastructure maintenance. Organizations should plan for hardware maintenance contracts, software support agreements, and internal team training to maintain system reliability without depending on external vendors for every issue. The complexity of AI infrastructure often justifies professional services partnerships to supplement internal capabilities during initial deployment and operation phases while building internal expertise over time.
How can organizations integrate local AI infrastructure with existing enterprise systems?
Enterprise integration requires careful planning for network connectivity, authentication systems, data access patterns, and application interfaces that bridge AI capabilities with existing business processes. Modern AI platforms provide APIs and integration frameworks that facilitate connection with enterprise data sources, business applications, and operational systems without requiring complete system replacements. The integration architecture should maintain security boundaries while enabling necessary data flow and system interaction that business users need to incorporate AI insights into their daily workflows.
What backup and disaster recovery considerations apply to AI infrastructure?
AI infrastructure backup strategies must account for large model files, training datasets, and configuration state that exceed traditional backup requirements by orders of magnitude. Recovery procedures should prioritize critical inference services while planning for longer recovery times for training infrastructure that can be rebuilt if necessary. Many organizations implement tiered recovery strategies that prioritize production inference capabilities over development and training systems during disaster scenarios, recognizing that business continuity depends on serving models rather than training new ones immediately.
How do organizations measure the success of their AI infrastructure investments?
Success measurement requires both technical and business metrics that demonstrate infrastructure value creation beyond simple uptime and utilization statistics. Technical metrics include system availability, performance benchmarks, and resource utilization efficiency that show the infrastructure performs as designed. Business metrics focus on AI application deployment velocity, developer productivity improvements, and operational cost reduction that translate technical capabilities into business outcomes. Regular assessment of these metrics guides optimization decisions and justifies continued infrastructure investment to executives who care more about business impact than technical specifications.
Conclusion
Infrastructure-first approaches to enterprise AI represent a fundamental shift from reactive to proactive deployment strategies that actually work in the real world. Organizations that prioritize robust foundations over quick wins position themselves for sustained AI success across multiple use cases and business functions. The evidence clearly demonstrates that thoughtful infrastructure planning reduces long-term costs while accelerating AI adoption throughout the enterprise. You can't build lasting AI capabilities on shaky foundations.
Local AI deployment strategies provide compelling advantages for organizations seeking cost predictability, enhanced security, and operational control that cloud providers simply cannot deliver. While cloud solutions offer flexibility for experimentation and pilot projects, production-scale AI implementations often benefit from on-premises infrastructure that delivers consistent performance and predictable economics without surprise bills or service disruptions. The key to success lies in matching infrastructure approaches to specific organizational requirements rather than following industry trends or vendor recommendations blindly. Your infrastructure choices today determine your AI capabilities tomorrow.
Last updated: June 2026
Blck Alpaca is a Vienna-based AI marketing automation agency specializing in data-driven marketing, custom AI agents, and enterprise workflow automation for businesses in the DACH region.
Related Articles
Discover more insights from our blog



{kind=link}
{kind=link}
{kind=link}
Never miss an insight
Subscribe to our newsletter and get AI & marketing trends delivered to your inbox.